业务背景
2022年1月4日,中国人民银行印发《金融科技发展规划(2022-2025年)》提出:“加快监管科技的全方位应用,强化数字化监管能力建设”。当前,银行网点对员工服务质量、环境秩序、疫情防控管理,尚存以下痛点:
值守难度大
银行网点工作环节多、人员流动大,现场管理难以实现全时段、全方位检查覆盖,人力值守难度大,效率低。
监督体制不健全
银行对网点合规要素、网点环境难以实现“点对点”有效实时监管,缺失风险流调溯源信息,大数据管理监督体制不健全。
内控管理不闭环
传统内控管理制度不完善,金融业务隐患风险排查与治理没有形成有效的闭环管理。
功能介绍
根据国家对金融科技发展的规划要求,以及银行网点推进数字化转型的实际需要,海康威视AI开放平台通过训练场景化AI算法,对银行网点内隐患事件进行检测并实时报警,有效保障网点安全、高效运转。
本案例主要是在银行场景中针对网点环境,网点合规性进行检测,分别如下:
1)针对防护舱内的银行卡、钱包、包、水瓶、人民币等遗留物品进行检测,将遗留的水瓶等杂物及时处理,提升网点整洁度;将客户遗留的钱包等物品及时归还,为客户提供更贴心服务。
2)针对银行网点消防设备存放处的灭火器进行检测,若未检测到灭火器设备及时预警上报,通知相关人员补充设备,保障银行网点的消防安全;针对垃圾箱外溢,垃圾箱上方有杂物进行检测,及时发现并处理,保证网点环境清洁。
算法模型训练完成后导入至边缘端设备或发布至云端,当边缘端检测到目标时,将推理结果上传给行业应用平台并将结果进行展示。
另外,第三方行业平台也通过调用相应接口实现上层应用。
价值成果
• 提升管理效率
智慧感知可视化平台整合银行营业网点风险隐患事件,告警联动网点巡管人员,实现可视管理,节省现场人员巡管时间。
• 增强服务体验
金融数字化管理服务体系,科学高效地解决银行营业网点在环境秩序、员工服务质量、疫情防控等方面存在的问题,减少风险事件,提高银行网点文明服务水平,打造智慧金融。
开发流程
1、登录海康威视AI开放平台官网:https://ai.hikvision.com/
2、注册AI开放平台账号;
3、使用AI开放平台训练算法。
利用AI开放平台训练算法,主要包括以下几个步骤:
步骤1:创建项目
步骤2:数据准备
步骤3:模型训练
步骤4:模型校验
步骤5:模型部署
步骤1:创建项目
在正式开始训练之前,需要创建一个物体检测模型,在【我的模型】界面,点击【创建模型】,进入创建模型界面,如下所示: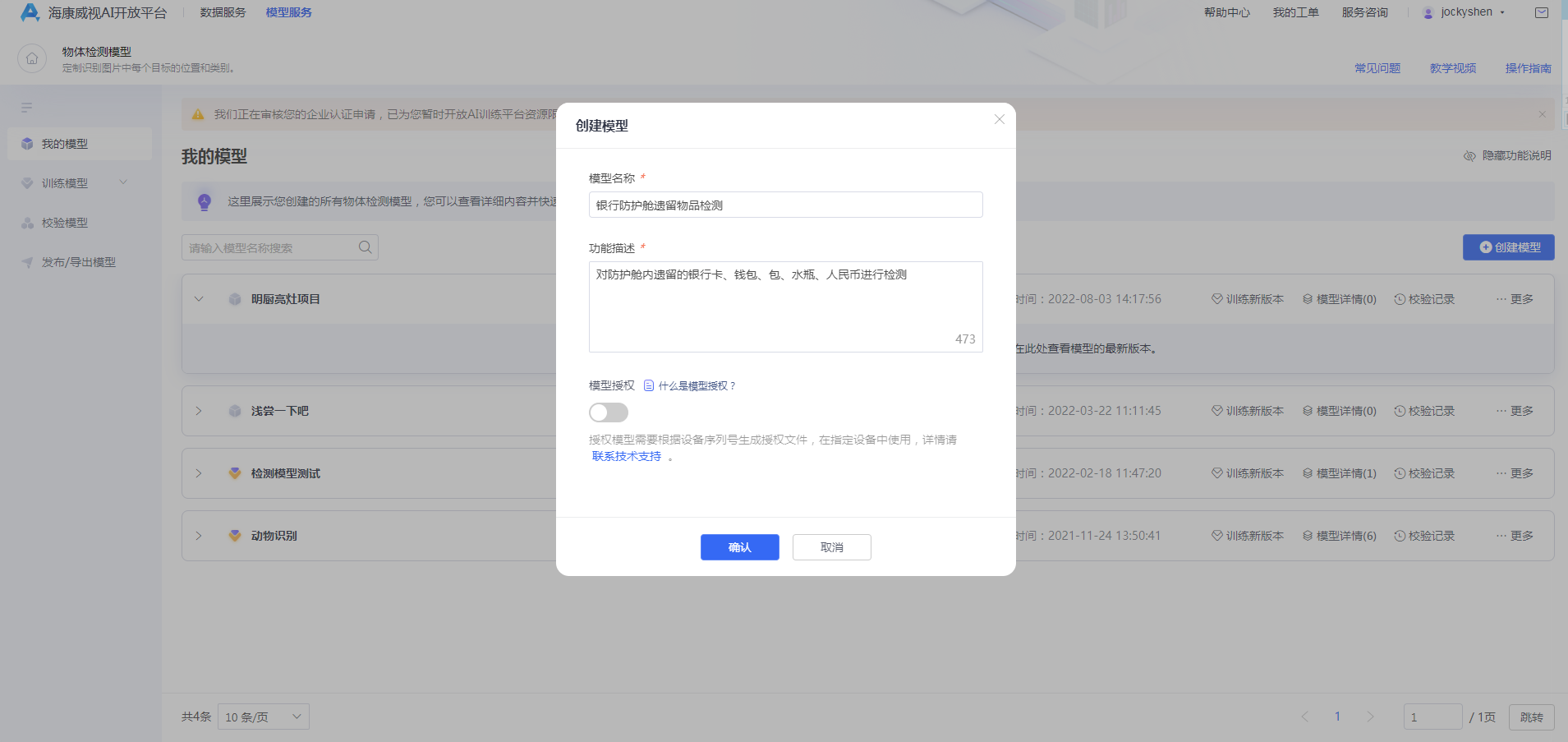
在填写模型名称和相关信息后,页面会回到我的模型主页面,提示“模型创建成功,若无数据集请前往数据服务创建,上传并标注数据集。训练模型后可在此处查看模型的最新版本”。
如果希望将算法和特定的AI设备绑定(需要授权文件),请勾选模型授权选项,需要注意的是,“模型授权”勾选后无法修改,需要慎重选择。
步骤2:准备数据
数据采集
素材收集在整个AI开放平台项目中是一个很关键的过程,素材质量的高低直接决定了算法模型的优劣。根据各个项目实际需求的不同,素材也可以从不同的场景与角度进行收集,达到充分覆盖现场需求场景的要求。
1)整体要求
图像质量高,目标清晰可见;
尽量采集真实应用场景下目标的真实特征;
尽量采集目标的不同类别和状态,通过肉眼可以进行区分;
检测模式下,目标在720P分辨率图像上的占比不得小于32X32像素,不同分辨率按此规则折算。
数据集创建
新建物体检测任务时候,首先需要创建新的数据集,具体步骤如下:
选择【数据总览】-【训练集】-【图片】-【创建训练集】,输入数据集名称,点击【确定】;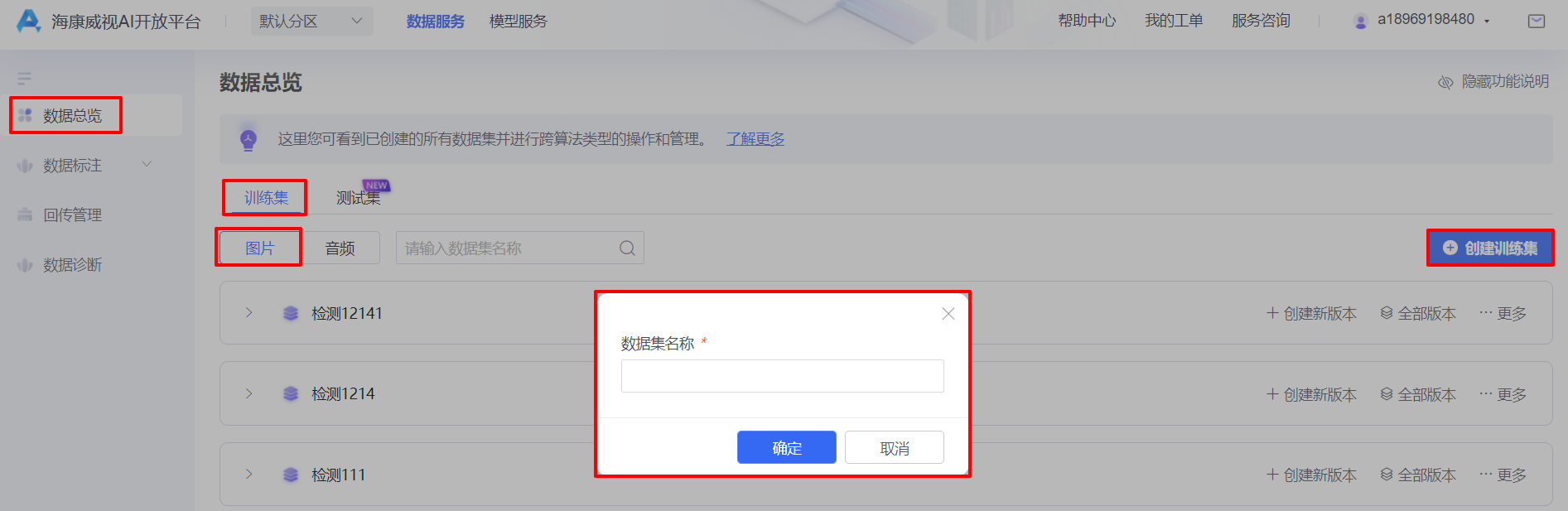
数据集创建后进行数据集版本的创建,创建数据集版本可实现数据跨算法类型和跨数据集功能,具体步骤如下:
选择【数据总览】-【训练集】,选择相应的数据集,点击【创建新版本】,选择创建方式、算法类型和标注方式,填写版本备注信息,点击【确定】。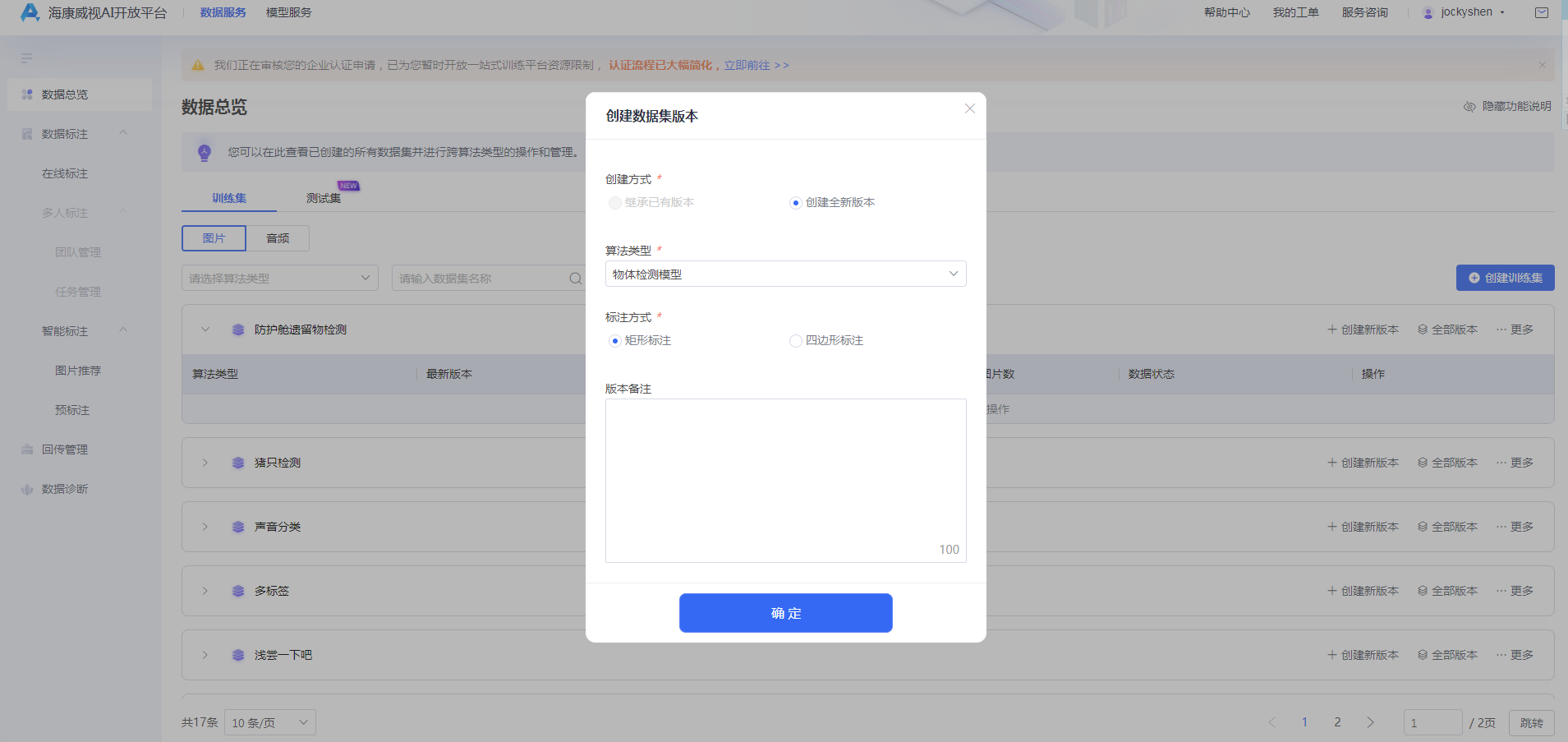
数据导入
海康AI开放平台提供两种数据上传方式,您可以选择通过web端或者客户端工具进行上传。以下以web端为例进行操作说明:
1) 在数据总览列表,选择相应的数据集版本,点击【导入】按钮,选择本地数据导入,在【选择导入方式】选择【不带标注导入】;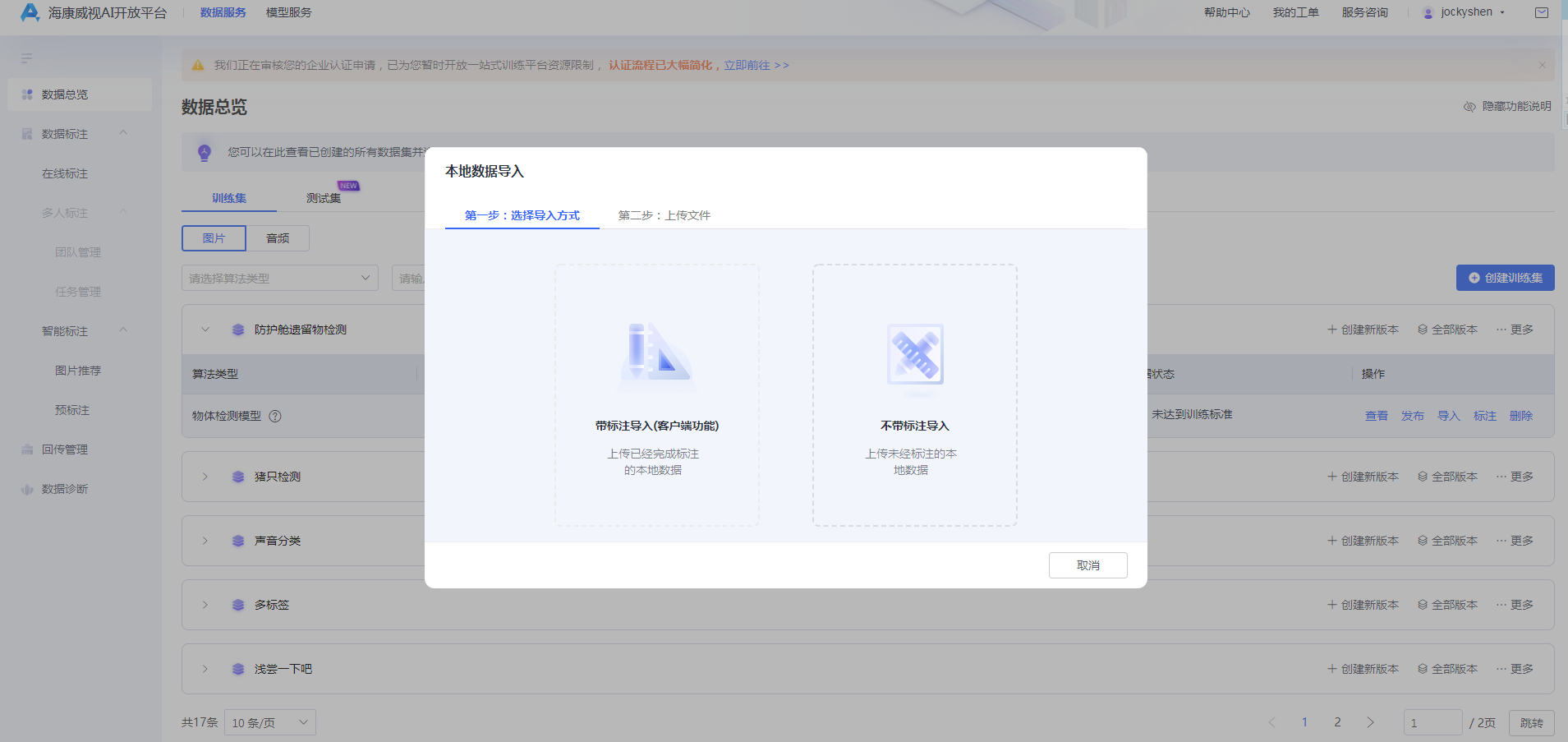
2) 选择图片上传或文件夹上传,设置是否需要去重,选择需要上传的数据,点击【上传数据】。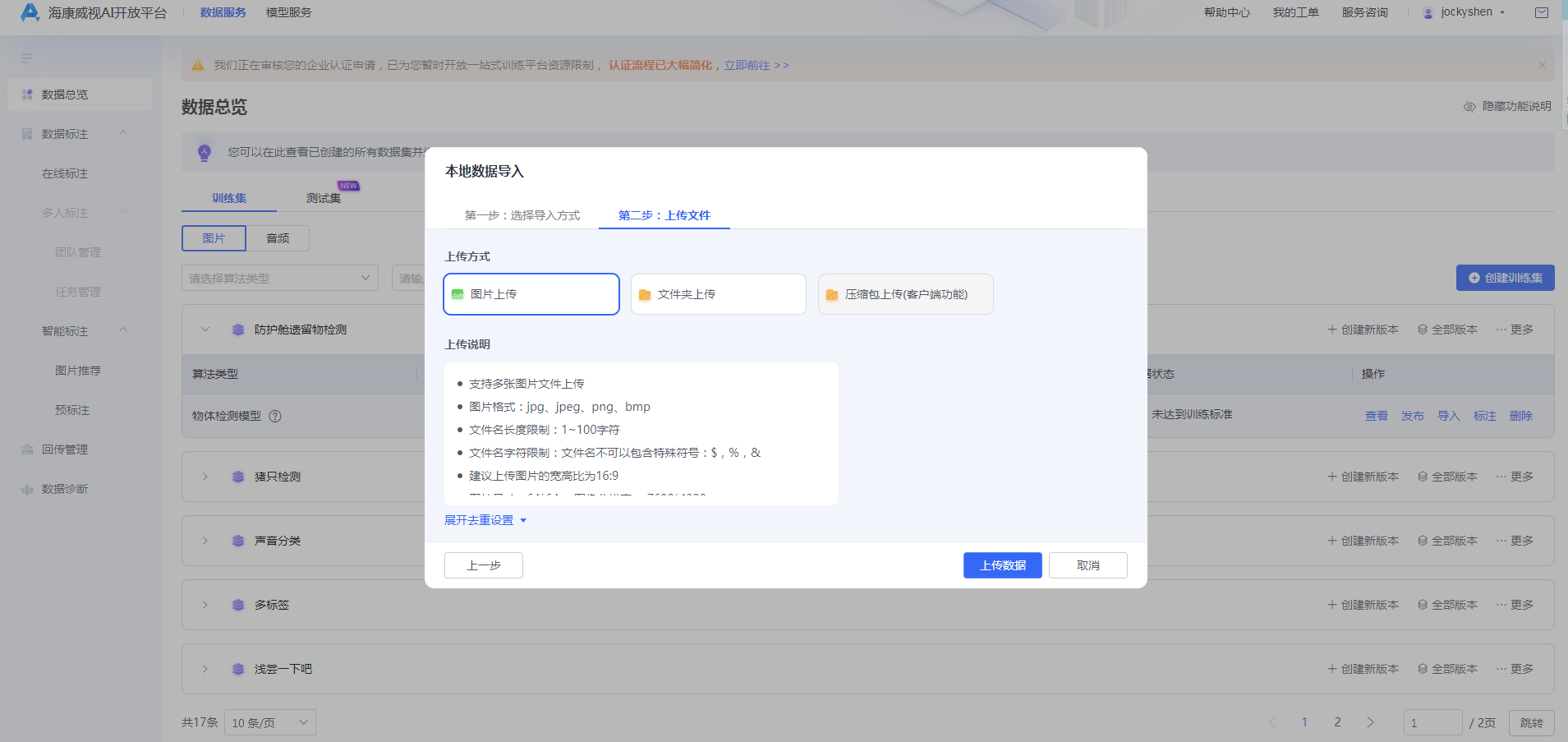
3) 在上传过程中可查看数据上传进度。
数据标注
本案例的基础功能点是检测防护舱内的遗留物品、垃圾桶满溢情况、是否存在灭火器以及工作岗位中是否有人,对物品和人员以画目标框的形式将图像中需要检测的目标进行标定,并打上检测标签;标定示例图如下: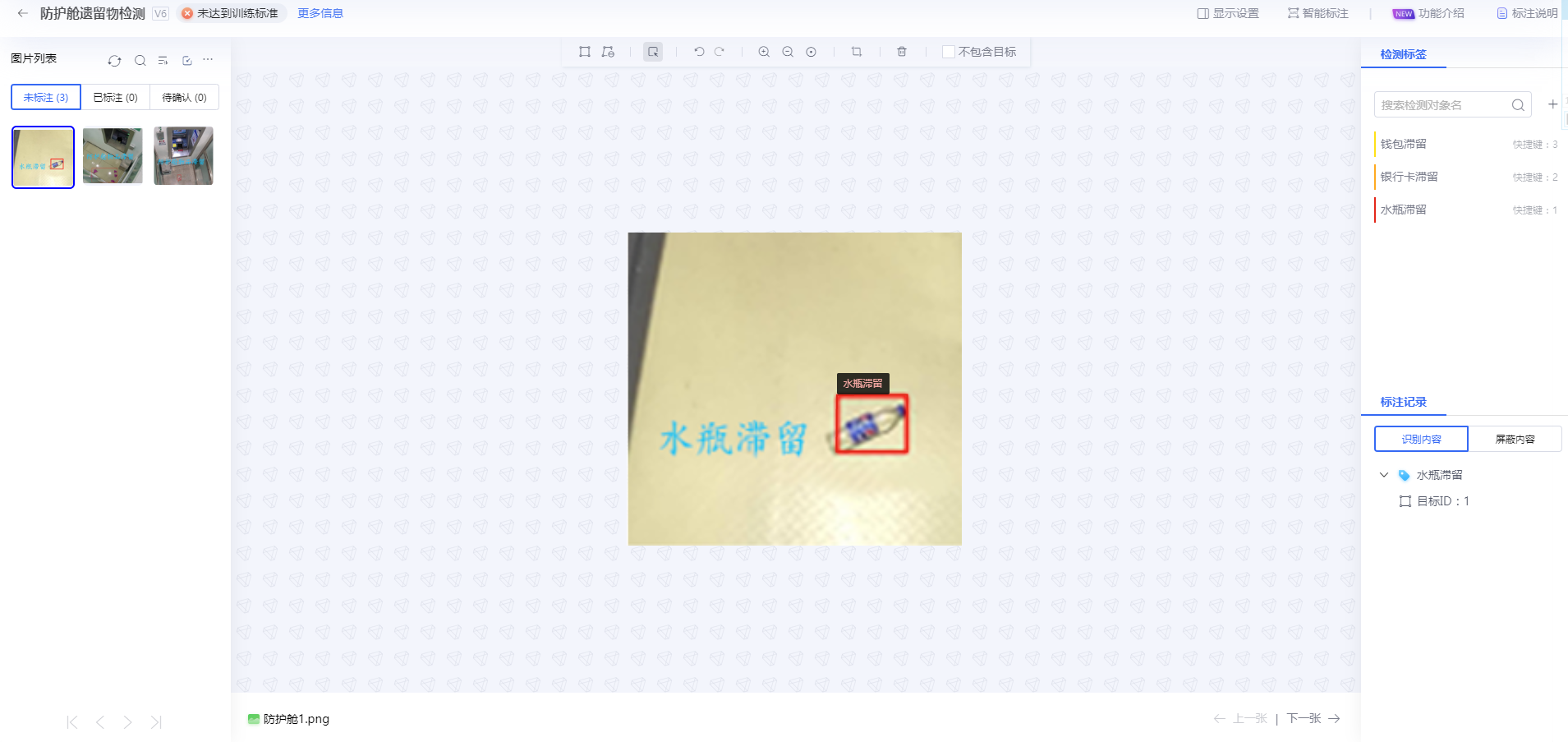
在数据标定的过程中,可以利用数据服务提供的功能来提升效率,使用工具栏的放大,缩小,裁剪等工具可以辅助标注,使用右侧添加标签时不同的标签会默认生成数字标签,画框后定级数字即可完成标签选定。标注同一类标签时候,可以自动继承标签内容,无需人工再次选择。
标注过程中,需要将矩形框尽可能的贴合检测目标,避免出现目标框过大过小、类别错标,漏标等。
标定过程中需要遵照以下规范进行:
1)目标框要求:
• 标定前请先选择标定矩形框或者四边形框;
• 目标框需紧贴目标;
• 单个目标框像素大小不低于32X32;
2)目标全标定:
• 图像中所有肉眼清晰可见,满足像素大小要求的检测对象都要标定出来,但每个目标需分开标定,一个框只标一个目标;
• 没有目标的样本,需要对整张图片标定目标框,并打上无目标标签,直接作为负样本加入训练集训练;
3)目标被遮挡/截断(目标在画中出现的比例)的标定:
• 遮挡/截断面积(目标在画中出现的比例)超过2/3以上的目标不需要标定;
• 遮挡/截断面积(目标在画中出现的比例)未超过2/3以上的目标,需要标定。遮挡部分不需要标定,按露出部分正常标定即可;
4)模糊情况下的标定:
• 人肉眼能看清的目标需要标定;
• 极端模糊的,人肉眼看不清的目标不需要标定;
5)标定方案统一:
同个项目同个功能的目标框标定区域要统一;例如检测图中的厨师帽,不能一个标整个人体,一个标人的厨师帽;这样会严重影响算法的训练效果。
如果标注的内容太多,可以创建标注团队,将标注任务分发给多人一起开展。也可以采用智能标注功能,基于当前标注阶段的标签,从用户的待标注数据中筛选具有更高标注优先级的图片,在减少标注量的同时达到接近全局标注的效果;
步骤3:模型训练
在模型训练完成后,需要在设备中进行使用。为了满足不同类型设备的要求,模型在训练时有差别,因此需要根据设备选择应用类型。
由于不同应用类型的模型不能够通用,因此在应用类型云部署、本地部署的选择上,可以根据实际的情况来配置。
云部署
云部署包含了在线验证和云眸部署两种。在线验证无法具体部署,但可以做验证模型效果时使用。云眸部署是指将训练好的算法直接部署在云端,通过接口调用的方式进行分析。这种方案不需要在项目中添加智能分析设备,但是需要对行业应用平台或第三方应用平台进行二次开发工作。
本地部署
本地部署包含了AI摄像机、AI超脑、AI服务器、AI物联网主机。
本地部署主要指将训练好的算法导入到设备中进行分析。例如AI摄像机是指将训练好的算法导入到AI摄像机内进行分析,不需要后端添加智能设备。这种方案对网络传输的带宽要求低,后端不需要添加智能设备,但是需要前端架设海康特定的AI摄像机。AI超脑、AI服务器是指将训练好的算法导入后端的智能设备中(NVR或T4 GPU服务器)进行分析。该方案前端设备仅作为数据采集的入口,所有的分析均在后端NVR中完成,对网络的带宽比较高,比较合适前端已有摄像机设备的场景。
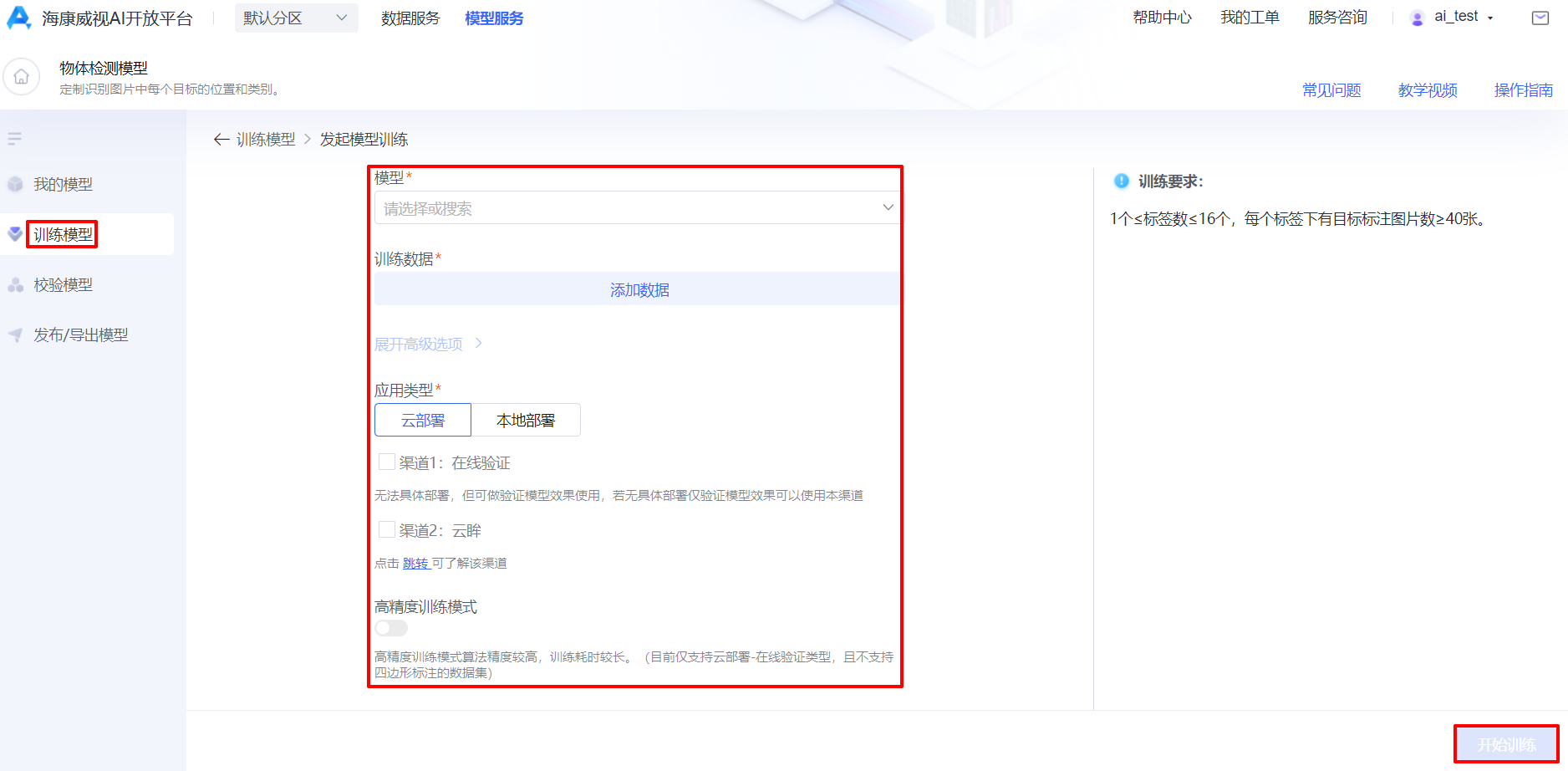
第一步:进入物体检测模型模块后,点击“训练模型”,在训练模型界面点击“创建训练”,进入模型训练界面。
第二步:选择应用类型,模型,数据集,勾选场景集,点击“开始训练”,即可启动模型的自动训练工作。根据数据量的不同,系统会预估完成的训练时间,在此过程中,关闭或者退出页面,系统后台仍然会执行训练操作。训练完成后,在“模型训练”页签中,可以查看当前算法模型的版本及评估报告。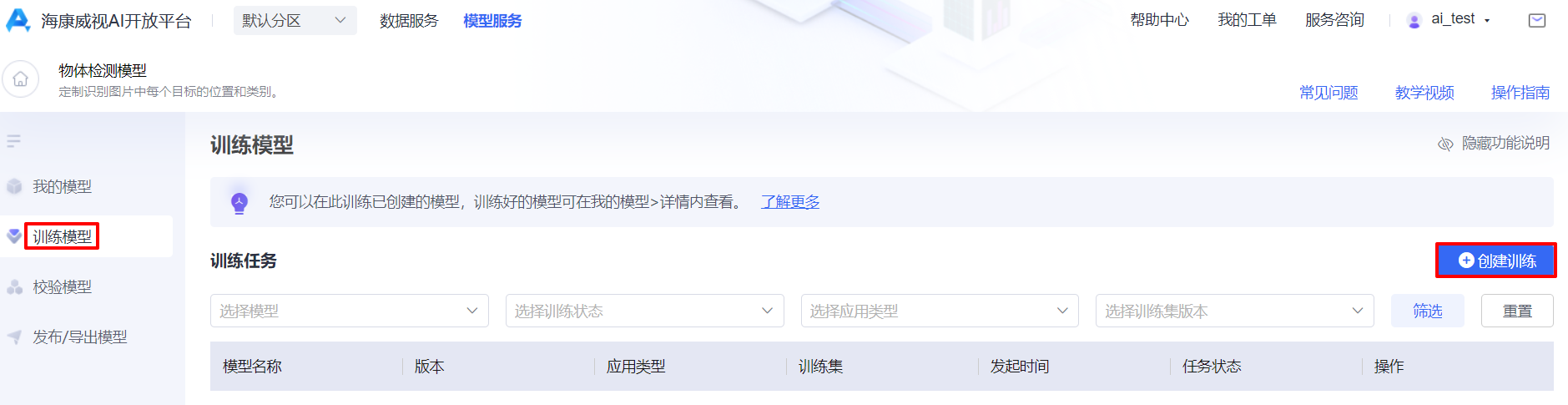
在评估报告中,可以通过百分比直观地看到模型性能的分析结果,如果模型性能一般,建议通过增加训练样本,同时检查标注信息的正确性(有无漏标、错标)。
步骤4:模型校验
模型校验可以从本地环境中上传图片进行校验,也可以通过创建测试集进行校验,以下以临时校验为例: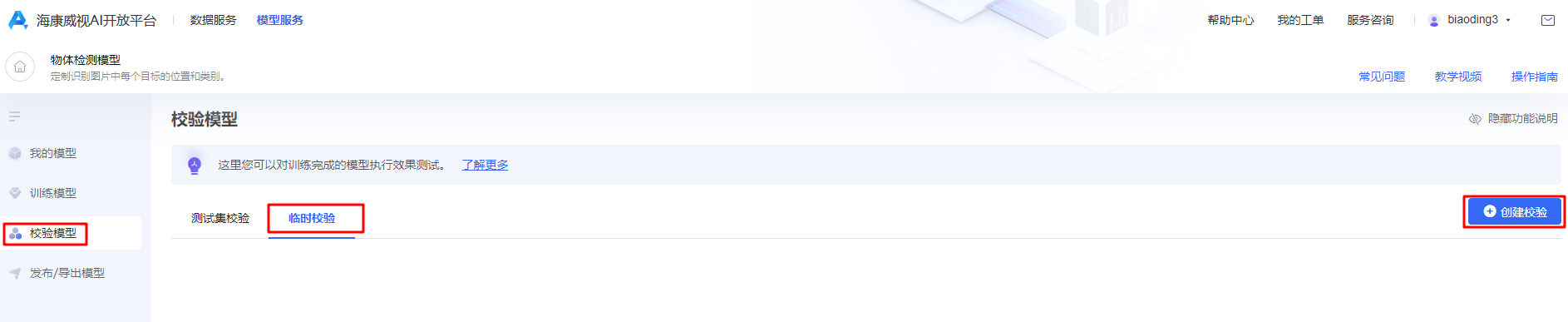
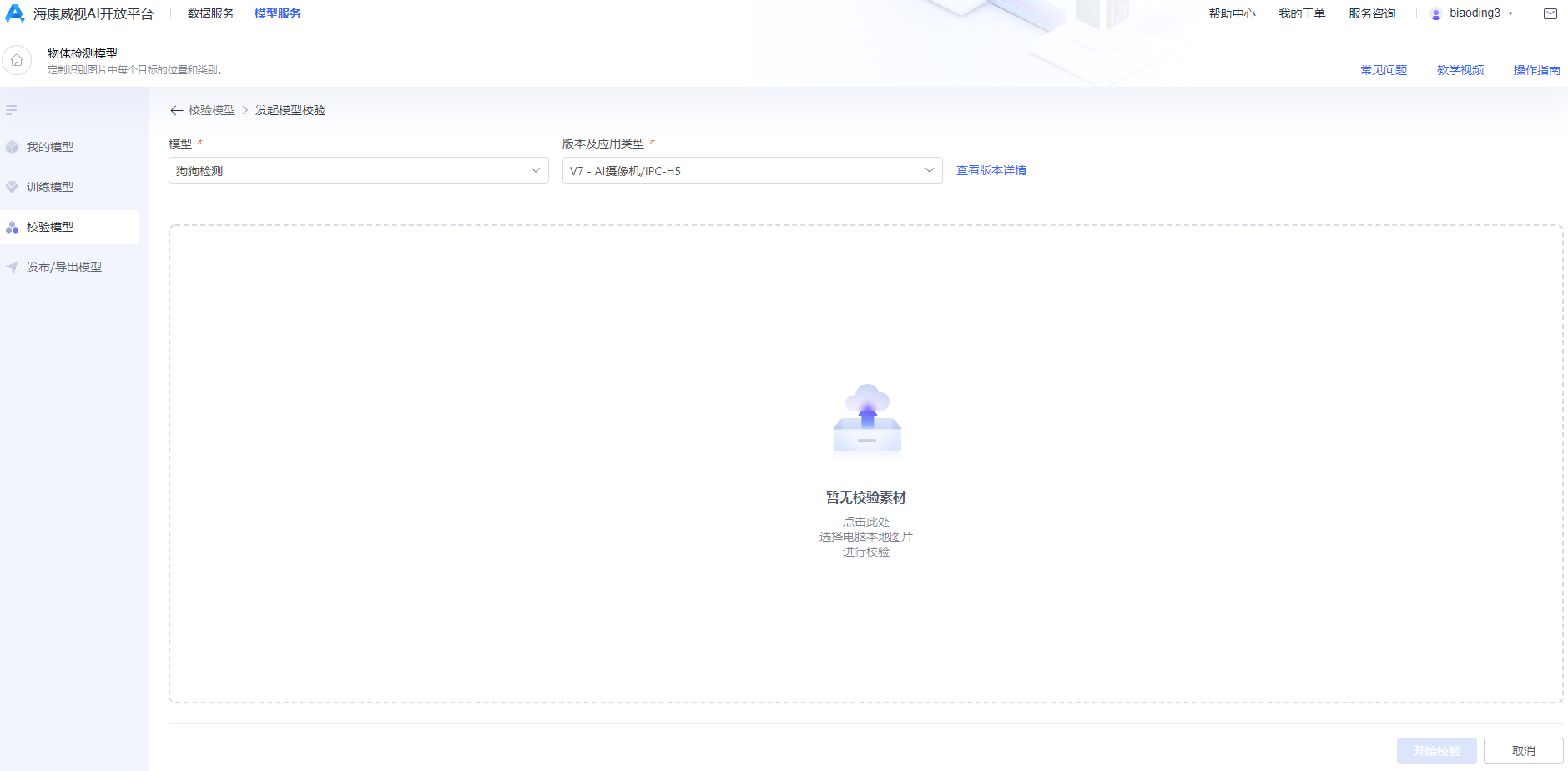
如模型准确率不满足预期,可在“数据集管理”步骤中添加图片并进行标注,重新进行模型训练及部署上线。
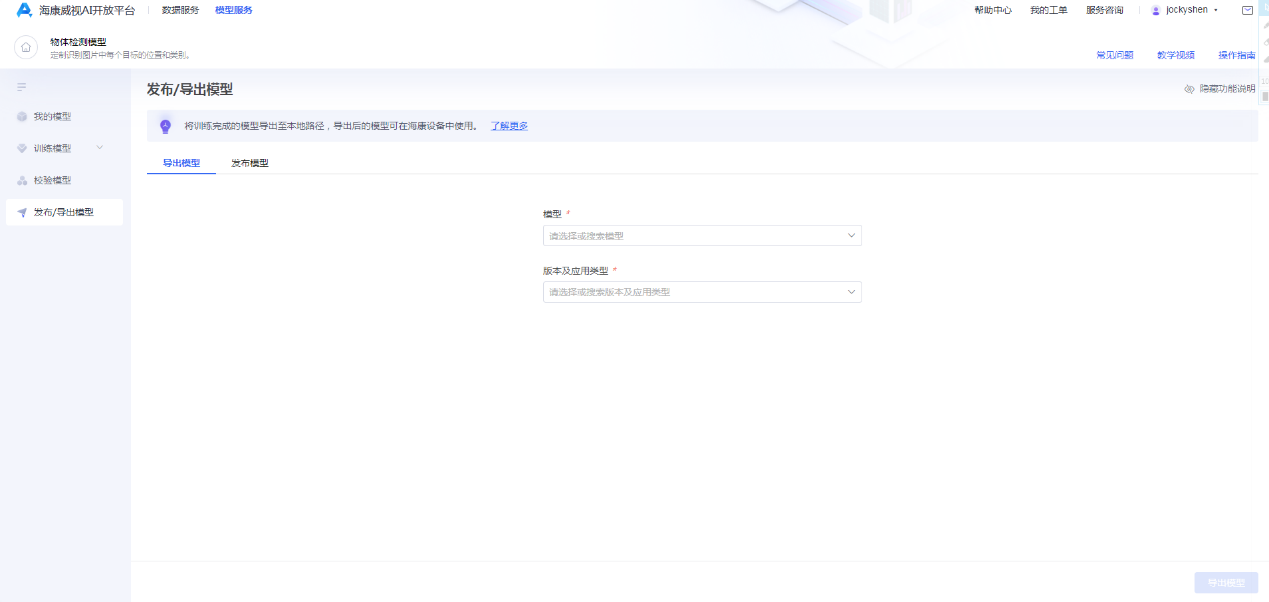
步骤5:导出/发布模型
对于小型的业务场景,可以选用AI摄像机,将训练完成的模型导出至本地路径,再将导出后的模型导入到AI摄像机中即可。对于集团化企业、中大型规模业务场景,可以选用普通摄像机 + AI超脑或者服务器的方案,将训练完成的模型导出至本地路径,再将导出后的模型导入到AI超脑或者服务器中即可。