没有记忆的AI,只是工具;有记忆的AI,才是资产。
很多使用 OpenClaw 的用户都知道,OpenClaw 本身是自带基础记忆机制的。在简单的几轮日常问答中,它确实能连贯上下文。但在深度使用、处理长周期复杂任务时,你是否经历过这些崩溃瞬间:
昨天刚跟 AI 敲定好的代码规范,今天新开一个对话,它又像不记得一样全忘了?为了彻底解决这些痛点,腾讯云 Lighthouse OpenClaw 现已无缝集成 TencentDB AI-Memory(腾讯云数据库 Agent Memory 服务)官方插件! 只需一键开启,即可让你的 Openclaw 的记忆力实现质的飞跃。
一、 站在巨人的肩膀上:TencentDB AI-Memory 带来了哪些能力增强?
在 OpenClaw 优秀的底层之上,TencentDB AI-Memory 插件针对复杂长任务场景,重点做了以下四大核心能力的增强:
1. 从“上下文跟随”升级为“核心偏好锁定”: 在超长轮次的对话中,有时会因信息过载而自然地将注意力转移到近期话题上。TencentDB AI-Memory 增强了对核心偏好的抓取能力,它能将你定下的约束条件(如代码规范、格式要求)稳稳“锁定”,确保无论聊多远,Agent 都不忘初心。
2. 跨会话的长周期任务无缝接力: 面对需要分多天完成的大型项目,增强插件能妥善保存你的任务进度和决策背景。明天新开一个会话,无需再把前置条件重新喂一遍,昨天聊到哪,今天继续接着干。
3. 更高精度的结构化信息召回: 针对你明确告知过的特定事实信息,TencentDB AI-Memory提供了一套独特的检索引擎。相比单纯依赖大模型的上下文窗口,它能实现更稳定、更精准的事实召回。
4. 多端统一的“独立大脑”体验: 通过插件化设计,Agent 的记忆实现了与单一会话实例的解耦。无论你是切换聊天窗口,还是更换聊天渠道,经过提炼的用户画像都能始终伴随,让体验高度统一。
同时 TencentDB AI-Memory 记忆增强插件完全将数据存放在Lighthouse本机上,且不会禁用 Openclaw 原生的Memory Core,两套记忆体系可以共存使用,相互补充。
二、 TencentDB AI-Memory 对记忆独特的增强方式
TencentDB AI-Memory 是腾讯云数据库团队自研的 Agent Memory 服务,它不再是简单的上下文堆叠,而是独创了四层渐进式记忆金字塔架构:
● L0 Raw Log(原始对话): 全量保留原始对话,确保任何细微信息都不丢失。
● L1 Atomic Memory(原子记忆): 自动从对话中提取高价值的“事实”、“偏好”与“约束条件”。
● L2 Scene Block(场景分块): 按场景对记忆进行聚类,形成特定的任务认知块,告别信息混乱。
● L3 Persona(用户画像): 持续提炼,生成稳定且长期的用户数字画像。

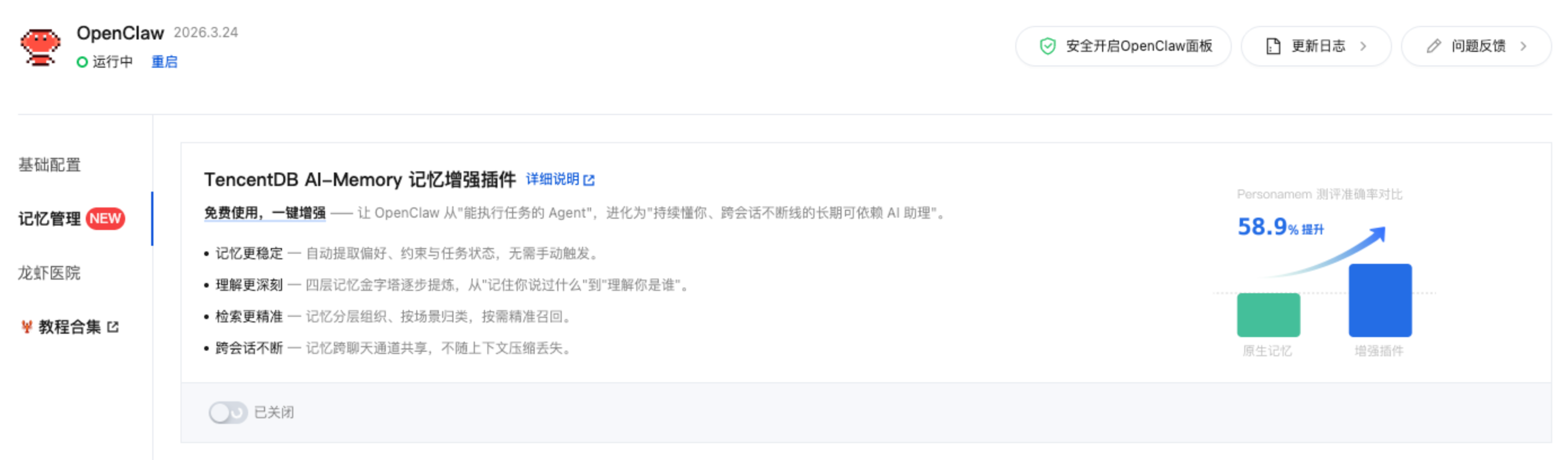
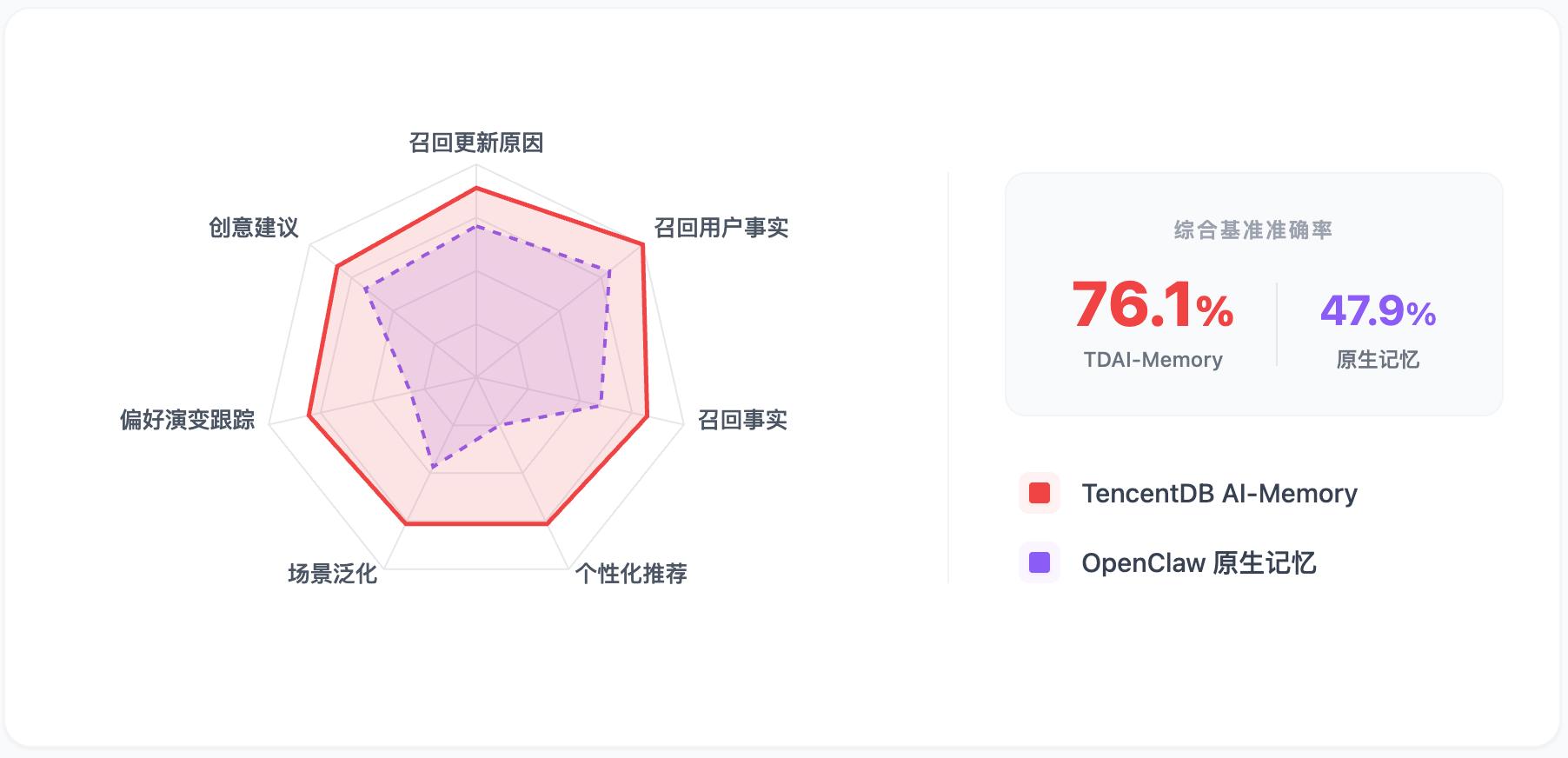
数据说话: 在权威的 PersonaMem 评测集中(模拟 20 了个用户,6000+ 条对话消息),使用 TencentDB AI-Memory 后Openclaw的回答总准确率高达 76.10%,而使用 OpenClaw 原生记忆仅为 47.85%,提升了58.9%! 尤其在“用户事实召回”指标上,从原生不到 30% 飙升至 79%+。(相当于从原本100个问题中只能回答对30个不到,提升至能回答对79问题)
三、 实战指南:一键开启 TencentDB AI-Memory记忆增强插件
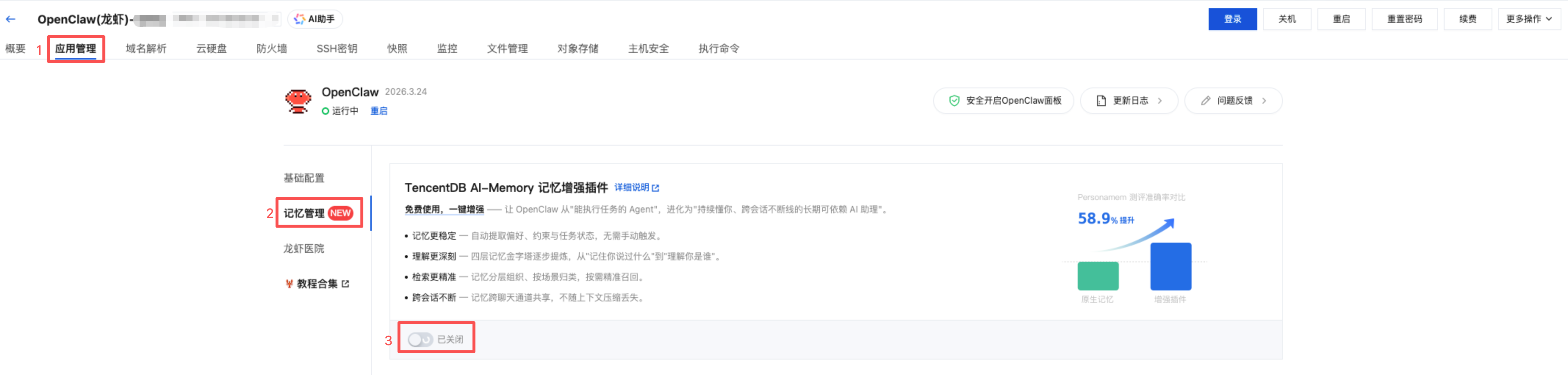
作为免单独安装的内置官方插件,TencentDB AI-Memory 已无缝集成到了腾讯云 Lighthouse 的应用管理界面中,可参考以下方式快速启用:
1. 进入腾讯云 LightHouse 控制台,进入你的 OpenClaw 实例;
2. 进入应用管理,再点击左侧的「记忆管理」,即可找到 TencentDB AI-Memory 记忆增强插件,将底部的开关拨动至“启用”状态;
3. 再点击弹窗中的“确认”后,将重启Gateway,待Gateway重新运行后即可使用。
四、 结语
通过无缝解耦的插件化设计以及独特的四层架构设计,TencentDB AI-Memory 记忆增强插件实现了让 OpenClaw 进化为“持续懂你、跨会话不断线的长期可依赖 AI 助理”。现在就登录腾讯云轻量应用服务器(Lighthouse)控制台,打开你的 OpenClaw,手动开启 TencentDB AI-Memory 记忆增强插件吧!
五、 补充说明
1. 配置 TencentDB AI-Memory 的 Embedding 依赖:
因 Openclaw 的本地 Embedding 功能对于 Lighthouse 服务器资源消耗较大,使用本地 Embedding 会出现明显的性能和体验问题,不建议使用本地资源进行Embedding模型推理,所以 TencentDB AI-Memory 默认不开启 Embedding(向量化语义检索),此时仅使用基础的基于关键字的 BM25 检索逻辑。
如果你想真正解锁 TencentDB AI-Memory 强大的“语义+关键词”双路精准检索能力,强烈建议配置远程 Embedding 服务。你可以登录 LightHouse 服务器,在 Openclaw 的配置文件(openclaw.json)中,单独配置远端 Embedding 模型相关的信息,配置完成后重启Gateway服务即可生效。
{
"plugins": {
"entries": {
"memory-tdai": {
"enabled": true,
"config": {
"embedding": { // 需配置自定义Embedding模型信息,非LLM模型
"enabled": true, //是否启用向量搜索
"provider": "openai", // 暂只支持OpenAI兼容的协议
"baseUrl": "https://xxx", //API Base URL
"apiKey": "xxx", //API Key
"model": "text-embedding-3-large", //模型名称
"dimensions": 1024 // 向量维度(需与所选模型匹配)
}
}
}
}
}}