长期记忆

长期记忆 让 QwenPaw 拥有跨对话的持久记忆能力:通过文件工具将关键信息写入 Markdown 文件长期保存,并配合语义检索随时召回。
长期记忆机制设计受 OpenClaw 启发,由 ReMe 的 ReMeLight 实现——以文件系统为存储后端,记忆即 Markdown 文件,可直接读取、编辑与迁移。
架构概览
用户 / AgentMemoryManager长期记忆管理记忆更新记忆索引更新记忆混合检索MEMORY.mdmemory/YYYY-MM-DD.md异步更新数据库向量语义搜索BM25 全文检索
长期记忆管理包含以下能力:
记忆文件结构
记忆采用纯 Markdown 文件存储,Agent 通过文件工具直接操作。默认工作空间使用以下层次结构:
{工作区}/
├── MEMORY.md ← Auto-Dream优化的长期记忆(结晶化)
│ 包含:核心决策、用户偏好、可复用经验
│
├── memory/ ← Auto-Memory写入的每日记忆(原始记录)
│ ├── 2026-04-20.md
│ ├── 2026-04-21.md ← Auto-Dream读取当日日志
│ └── ...
│
└── backup/ ← Auto-Dream创建的备份
├── memory_backup_20260421_230000.md
└── ... ← 可用于恢复历史版本MEMORY.md(长期记忆,可选)
存放长期有效、极少变动的关键信息。
位置:
{working_dir}/MEMORY.md用途:存储决策、偏好、持久性事实、经验教训
更新:Agent 通过
write/edit文件工具写入,或通过 Auto-Dream 自动优化
memory/YYYY-MM-DD.md(每日日志)
每天一页,追加写入,记录当天的工作与交互。
位置:
{working_dir}/memory/YYYY-MM-DD.md用途:记录日常笔记和运行上下文
更新:Agent 通过
write/edit文件工具追加写入,对话过长需要进行总结时自动触发角色:作为 Auto-Dream 优化的输入源
backup/(备份目录)
存储 Auto-Dream 优化前的 MEMORY.md 备份文件。
位置:
{working_dir}/backup/用途:每次 Auto-Dream 执行前自动创建备份,可用于恢复历史版本
命名格式:
memory_backup_YYYYMMDD_HHMMSS.md
关于 Auto-Memory、Auto-Dream、Auto-Memory-Search 和 Proactive 的完整工作流介绍,请参阅 智能体记忆进化与主动交互。以下仅补充技术实现细节与配置说明。
搜索记忆
Agent 有两种方式找回过去的记忆:
混合检索原理
记忆搜索默认采用向量 + BM25 混合检索,两种检索方式各有所长,互为补充。
向量语义搜索
将文本映射到高维向量空间,通过余弦相似度衡量语义距离,能捕捉意义相近但措辞不同的内容:
但向量搜索对精确、高信号的 token 表现较弱,因为嵌入模型倾向于捕捉整体语义而非单个 token 的精确匹配。
BM25 全文检索
基于词频统计进行子串匹配,对精确 token 命中效果极佳,但在语义理解(同义词、改写)方面较弱。
打分逻辑:将查询拆分为词,统计每个词在目标文本中的命中比例,并为完整短语匹配提供加分:
base_score = 命中词数 / 查询总词数 # 范围 [0, 1] phrase_bonus = 0.2(仅当多词查询且完整短语匹配时) score = min(1.0, base_score + phrase_bonus) # 上限 1.0
示例:查询 "数据库 连接 超时" 命中一段只包含 "数据库" 和 "超时" 的文本 → base_score = 2/3 ≈ 0.67,无完整短语匹配 → score = 0.67
为了处理 ChromaDB
$contains的大小写敏感问题,检索时会自动生成每个词的多种大小写变体(原文、小写、首字母大写、全大写),提高召回率。
混合检索融合
同时使用向量和 BM25 两路召回信号,对结果进行加权融合(默认向量权重 0.7,BM25 权重 0.3):
扩大候选池:将最终需要的结果数乘以
candidate_multiplier(默认 3 倍,上限 200),两路分别检索更多候选独立打分:向量和 BM25 各自返回带分数的结果列表
加权合并:按 chunk 的唯一标识(
path + start_line + end_line)去重融合仅被向量召回 →
final_score = vector_score × 0.7仅被 BM25 召回 →
final_score = bm25_score × 0.3两路都召回 →
final_score = vector_score × 0.7 + bm25_score × 0.3排序截断:按
final_score降序排列,返回 top-N 结果
示例:查询 "handleWebSocketReconnect 断线重连"
搜索查询向量语义搜索 x0.7BM25 全文检索 x0.3按 chunk 去重 + 加权求和按融合分数降序排列返回 top-N 结果
总结:单独使用任何一种检索方式都存在盲区。混合检索让两种信号互补,无论是「自然语言提问」还是「精确查找」,都能获得可靠的召回结果。
记忆配置
配置结构
记忆配置位于 agent.json 的 running.reme_light_memory_config 中:
自动记忆搜索配置
在 running.reme_light_memory_config.auto_memory_search_config 中配置:
Embedding 配置(可选)
Embedding 配置用于向量语义搜索,位于 running.reme_light_memory_config.embedding_model_config:
use_dimensions用于某些 vLLM 模型不支持 dimensions 参数的情况,设为false可跳过该参数。
通过环境变量配置(Fallback)
当配置文件中未设置时,以下环境变量作为 fallback:
base_url和model_name都非空才能开启混合检索中的向量检索(api_key不参与判断)。
全文检索配置
通过环境变量 FTS_ENABLED 控制是否启用 BM25 全文检索:
即使不配置 Embedding,启用全文检索仍可通过 BM25 进行关键词搜索。
底层数据库
通过 MEMORY_STORE_BACKEND 环境变量配置记忆存储后端:
存储后端说明:
推荐:使用默认的
auto模式,系统会根据平台自动选择最稳定的后端。
其他 Memory Backend
QwenPaw 的记忆系统采用可插拔的 Backend 架构。除了默认的 ReMeLight(本地文件存储)外,还支持通过 memory_manager_backend 切换到其他后端。
ADBPG(AnalyticDB for PostgreSQL)
基于云端向量数据库的长期记忆后端,适合需要跨设备共享、大规模语义检索的场景。
核心特点:
跨会话持久化 — 记忆存储在云端数据库,重启后不丢失,支持多设备共享
服务端事实抽取 — 由 ADBPG 内置 LLM 完成事实提取,客户端无额外开销
双 API 模式 — 支持 SQL 直连和 REST API 两种接入方式
优雅降级 — ADBPG 不可达时 Agent 正常运行,仅长期记忆功能暂时禁用
配置方式:
进入 Agent 配置页面的「运行配置」标签,找到「记忆管理后端」下拉框,选择 adbpg,并在下方的 adbpg_memory_config 中根据所选 API 模式填写对应参数。
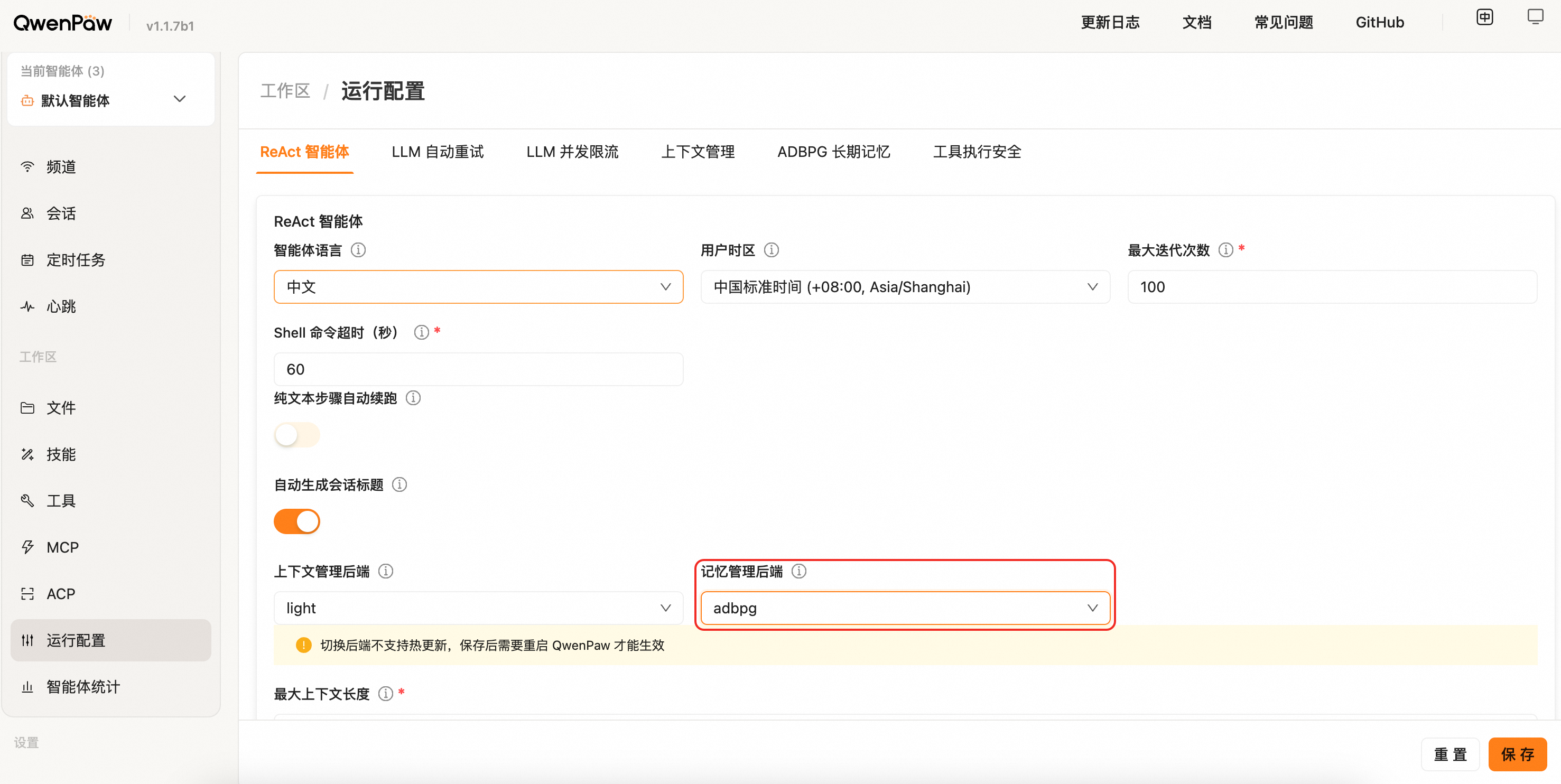
⚠️ 切换后端不支持热更新,保存后需要重启 QwenPaw 才能生效(页面也会以黄色横幅提醒)。
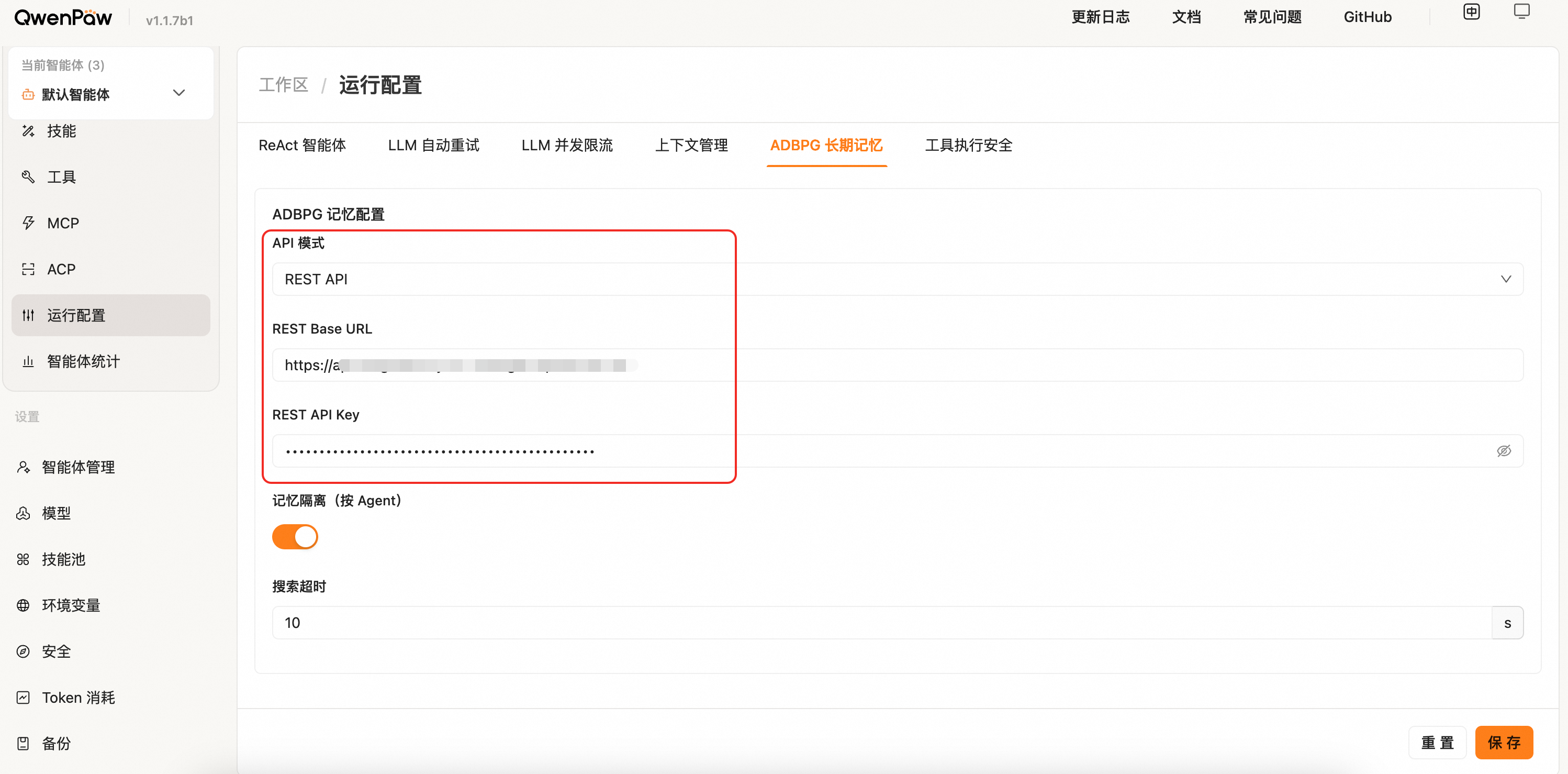
REST 模式(推荐)
通过 HTTP API 接入 ADBPG 记忆服务,无需额外 Python 依赖。
切换到「ADBPG 长期记忆」Tab,将「API 模式」设为 REST API,并填写 REST Base URL 与 REST API Key:
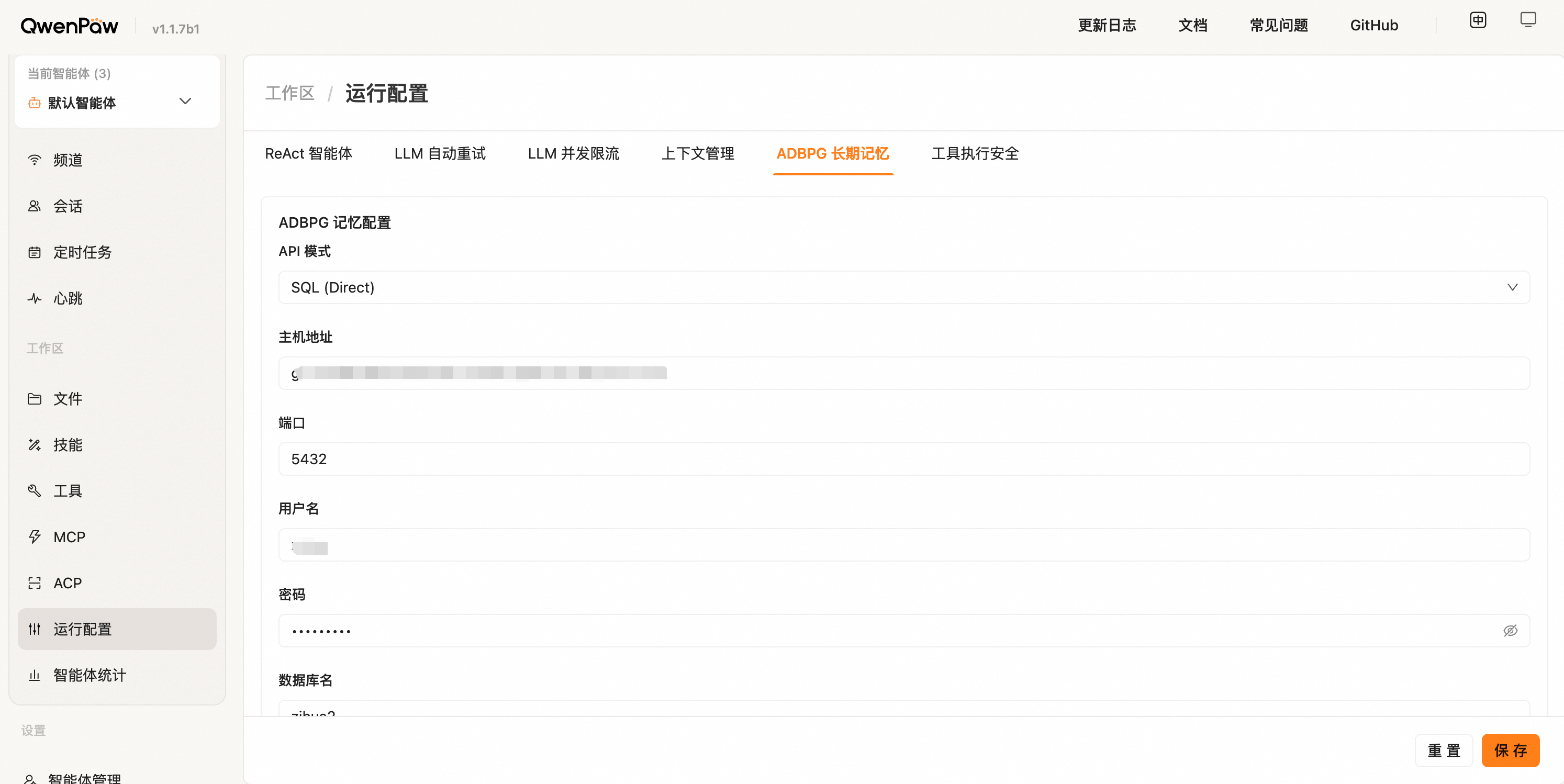
SQL 模式
通过 psycopg2 直连 ADBPG 数据库,需额外安装依赖:pip install qwenpaw[adbpg]。
切换到「ADBPG 长期记忆」Tab,将「API 模式」设为 SQL (Direct),并填写数据库连接信息(主机地址 / 端口 / 用户名 / 密码 / 数据库名)以及 LLM、Embedding 相关参数:
配置示例:
完整配置可写入 agent.json 的 running.adbpg_memory_config 字段:
{
"running": {
"memory_manager_backend": "adbpg",
"adbpg_memory_config": {
"host": "gp-xxxxxxxxx-master.gpdb.rds.aliyuncs.com",
"port": 5432,
"user": "your_db_user",
"password": "your_db_password",
"dbname": "your_db_name",
"llm_model": "qwen-plus",
"llm_api_key": "sk-xxxxxxxx",
"llm_base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"embedding_model": "text-embedding-v3",
"embedding_api_key": "sk-xxxxxxxx",
"embedding_base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"embedding_dims": 1024,
"api_mode": "sql",
"rest_api_key": "",
"rest_base_url": "",
"memory_isolation": true,
"search_timeout": 10.0,
"pool_minconn": 1,
"pool_maxconn": 5
}
}}💡 通过 Console 「运行配置」页面填写时,框架会自动将这些字段写入
agent.json,无需手动编辑文件。
相关页面
智能体记忆进化 — Auto-Memory、Auto-Dream、Auto-Memory-Search、Proactive 完整工作流
项目介绍 — 这个项目可以做什么
控制台 — 在控制台管理记忆与配置
Skills — 内置与自定义能力
配置与工作目录 — 工作目录与 config
智能体记忆进化与主动交互(Beta)

Beta 功能:智能体记忆进化与主动交互是 QwenPaw 在 1.1.4beta1 之后版本中提供的实验性能力。我们围绕"记忆驱动的经验闭环"
做了一些探索,目前仍处于持续迭代阶段。如果你在使用中有任何想法或建议,欢迎在 GitHub 提出,帮助我们把它做得更好。
QwenPaw 的智能体不依赖模型微调,而是通过记忆驱动的经验闭环实现持续进化——越用越聪明,并在此基础上实现主动交互。核心思路是:让 Agent 在每次交互中积累经验、定期反思提炼、主动检索复用、最终形成个性化服务能力,从被动响应走向主动服务。
进化闭环
记忆进化并非单一功能,而是四个模块协同形成的闭环:
四个阶段形成正向循环:Proactive 产生的新交互又被 Auto-Memory 沉淀,推动下一轮进化。
快速上手
推荐的完整进化链路配置:
一句话总结:边做边记 → 定期整理 → 马上能用 → 主动服务。Agent 通过这个闭环,在不改模型的情况下持续进化。
第一步:经验积累(Auto-Memory)
Auto-Memory 是进化的起点。它让 Agent 做更加全面的总结——**不仅仅是记住之前发生了什么,更重要的是总结之前做事的经验和反思,思考如何在下一次事情中做得更好 **。这是记忆进化的核心:每次交互都是一次学习机会。
记录什么
经验反思是记忆进化的关键——它的核心目标是构建可复用的认知框架,以改善未来的任务执行。Agent 从"做过的事"中提炼出" 做事的方法",从"我做了什么"进化到"我下次怎么做更好"。
怎么记录
Auto-Memory 不是简单地追加新内容,而是与当日已有的记忆文件进行智能合并:
分类清晰:明确区分"事实记忆"与"反思与逻辑"两大类
避免重复:已记录的信息不会重复写入
丰富细节:相关条目会用新信息补充完善
保持时序:在适用时保持时间顺序,始终保留时间戳
简洁完整:只添加真正新的或有丰富价值的信息,保持条目简洁但完整
如果没有新的内容可存储或反思,Auto-Memory 会静默跳过(回复 [SILENT]),不产生额外的 token 消耗。
何时记录
默认关闭,因为周期性触发会带来额外的高频 token 消耗。需手动开启:
配置路径:工作区 → 运行配置 → 长期记忆 → 自动记忆间隔
配置建议:推荐设为 310,即每 310 轮对话进行一次反思总结。如果希望更积极地积累经验,可以设为 1——每轮用户 query 都会进行总结。频率越高,经验积累越快,token 消耗也越大。此过程在后台自动执行,不影响当前对话体验。
第二步:记忆整理(Auto-Dream)
日常积累的记忆不可避免地包含重复、冲突和缺乏结构的内容。Auto-Dream 默认开启,每天晚上 11 点自动执行一次,将原始记忆" 结晶化"为高质量知识。一天一次的整理频率,token 消耗相对可控。
配置路径:工作区 → 运行配置 → 长期记忆 → 梦境
五大优化原则
整理结果
优化后的内容写入 {工作区}/MEMORY.md,包含三类高价值信息:
核心业务决策
已确认的用户偏好
高价值可复用经验
注意:
MEMORY.md默认不进入上下文。如需 Agent 在对话中自动使用,需在工作区 → 文件中手动开启MEMORY.md的开关,总是加载到上下文。
第三步:经验检索(Auto-Memory-Search)
积累和整理之后,关键在于让 Agent 主动使用这些经验。然而在实际使用中,弱模型往往不擅长主动调用记忆检索工具——它们不会在需要时自觉地去翻阅历史经验。Auto-Memory-Search 就是为了解决这个问题:在每轮对话开始前自动检索相关记忆,注入推理上下文,帮助弱模型也能用好记忆。
工作流程
用户发送消息 ↓ 提取消息文本作为查询(最多 100 字符) ↓ 检索 MEMORY.md + memory/*.md ↓ 将检索结果作为已完成的工具调用注入消息历史 ↓ Agent 基于历史经验进行推理
与传统 RAG 的区别
检索结果以"已完成的工具调用"形式注入,而非拼接到 system prompt。这种方式保持了 KVCache 的完整性,显著提高 token 使用效率。
效果对比
以"查询阿里巴巴股价"为例:
配置项
注意:默认关闭,需手动开启。
配置路径:工作区 → 运行配置 → 长期记忆 → 自动记忆搜索 → 打开「自动记忆搜索(Beta)」开关,可进一步设置最大结果数和最低相关性分数。
第四步:主动服务(Proactive)
当记忆系统足够丰富时,Agent 可以从被动响应进化为主动服务——基于对用户的理解,预测需求并推送有价值的信息。
典型场景
推送用户关心话题的最新进展(如"今日股市行情")
重试历史会话中未完成的任务
为正在进行的工作补充信息(如相关学术调研)
感知用户正在处理 PR,主动提供代码审查意见
运行机制
默认关闭,开启后会增加额外的 token 消耗。通过超级命令开启:
/proactive # 使用默认间隔(空闲 30 分钟后触发) /proactive 15 # 设置空闲 15 分钟后触发 /proactive off # 关闭主动服务
应用空闲指定时间后触发,整体流程:
记忆聚合 — 提取近期对话、用户兴趣点、未完成任务
需求预测 — 基于上下文推测潜在需求
信息检索与推送 — 调用工具获取最新信息,生成主动消息
推送消息以 [PROACTIVE] 前缀标识,发送至专用 session。
防打扰策略
推送后若用户无操作,不会重复触发相同内容
仅提供信息/建议/提醒,不执行高风险操作(如修改文件、发送请求)
使用方式
后续规划
当前的记忆进化能力基于 ReMe 的 ReMeLight 实现。ReMe 正在进行一次大规模代码重构,重构完成后将为记忆进化带来质的提升:
更精细的记忆分类
记忆不再只是"事实"与"反思"的二分法,而是细分为三类:
差异化的创建与更新策略
不同类型的记忆有不同的生命周期和更新逻辑,重构后将为每种类型实现专属的创建与更新方案:
这种差异化策略确保每种记忆都能以最适合的方式生长和演进,而非一刀切地套用同一种逻辑。其中 Procedural 记忆将拥有专属的 Summarizer,专门提炼"怎么做更好"的经验——这是记忆进化的核心驱动力。
Knowledge 知识图谱
Knowledge 类型记忆将支持 Graph Markdown 格式,构建结构化的知识图谱。Agent 不再只是"记住了一堆零散信息",而是建立起信息之间的关联关系,形成可推理的知识网络。
以上所有模块(Auto-Memory、Auto-Dream、Auto-Memory-Search、Proactive)都将在 ReMe 新框架下统一重构,获得更好的架构支撑和更一致的体验。